

自主智能体的持续学习:从轨迹建模到策略梯度
一、Agent 系统的”不会学”困境
过去两年,基于 LLM 的 Agent 系统发展迅猛。在典型的企业级 Agent 平台中,往往已经运行着多种职能的智能体:自动化工作流、知识库问答、办公助理、智能客服、代码助手、数据分析Agent 等等。但当我们仔细观察这些系统的“进化方式”,会发现一个共同模式:一旦出现新问题,常见的应对手段——修改 Prompt、补充行业知识库、或切换更大的模型。这种模式带来一个隐含但关键的观察:一个只负责执行指令的 Agent,其能力边界在上线那一刻基本已经确定,其上限始终受限于人类的设计与维护能力。
然而,Agent 的潜力远不止于“更强的自动化工具”。它真正可能带来的,是对复杂问题求解方式的范式级改变——那些原本需要多年经验积累的问题,有机会被系统性加速。这也迫使我们回到一个更本质的问题:**能否让 Agent 在工作过程中自主学习?**只有当 Agent 能够在交互中积累经验、在反馈中持续优化策略,它才可能突破“静态能力”的边界,成为一个真正演化的系统。
本文分享的正是我们在构建新一代智能体平台EKC2.0过程中对这一问题的思考与探索。
如果我们希望 Agent 能够在实际工作中不断进化,一个几乎不可回避的方向就是引入强化学习(Reinforcement Learning)。从直觉上看,这似乎是一个自然的延伸:让 Agent 在任务执行中根据反馈优化行为策略。但当我们真正尝试把 RL 引入 Agent 系统时,很快发现,这并不是 RLHF 的简单放大版本,而是一个复杂得多的问题。
二、Agent RL 为什么比 RLHF 难一个数量级
很多人觉得 Agent RL 就是”给 Agent 加个奖励函数然后训”。我们最初也这么想,实际做下来发现,难度比预期高了至少一个数量级。本质困难有三个:
长轨迹的信用分配
ChatGPT 的 RLHF 工作在 token 级别:一个 response 好不好,直接打分,干净利落。
Agent 的问题是:一个任务可能需要五到十步:提出问题→文献检索→构思假设→实验设计→数据收集与分析→撰写论文。最后成功了,功劳该归哪一步?中间某步调错了web_search(xxxx), 但最终实验结果碰巧对了,算不算好?
这是经典的 credit assignment 问题,但在 Agent 场景下每一步的 action space 不是几个离散按钮,而是”调用哪个工具 × 传什么参数”的组合爆炸。
开放环境的不确定性
Agent 所面对的环境本质上不是经典的 MDP,而是一个部分可观测、动态变化的环境,下围棋的环境是封闭的、确定性的。Agent 面对的是真实世界:MCP API 可能超时,hooks可能返回异常格式,skill的工具组合不可预测。
同样的 action,今天调通了,明天 API 改了版本就报错了。Agent 在面临这种高度不确定的环境交互(特别是复杂的工具调用步骤)时,动作空间的熵会急剧上升,训练时的模拟环境再怎么做也和生产有 gap。
奖励信号的模糊性
做数学题有精确答案,下棋有输赢。但企业场景下的大多数 Agent 任务,“好”的定义本身就是模糊的。售前 Agent 回答得很专业,但客户没留联系方式——这算好还是不好?售后 Agent 解决了问题但用户说”你反应太慢了”——给几分?内部知识问答 Agent 给了正确答案,但引用的文档已经过期——怎么评?任务成功与否常依赖上下文、隐性约束或动态价值观,单一标量奖励无法覆盖多维对齐目标,因此真正的难度不在算法。难的是把业务语义翻译成数学信号。
三、换一种方式理解 Agent:它是轨迹生成器
搞清楚了难点,下一步是找到对的建模方式。这一步对了,后面的系统设计才不会跑偏。
我们最初的心智模型是把 Agent 当成”一个会调工具的聊天机器人”,后来发现这个理解太浅了。
传统 LLM 是 token generator——给一个 prompt,一个 token 一个 token 地吐出回答。
对于 LLM:• 状态 s:当前上下文(prompt + 已生成内容)• 动作 a:下一个 token 或推理步骤• 奖励 r:来自奖励模型或规则验证器
但 Agent 做的事情不是一次性的文本生成,而是一连串的观察、思考、行动、反馈:
观察当前状况→ 思考下一步 → 执行动作 → 拿到反馈 → 再观察 → 再思考 → …
每一轮都是一个决策点。把这些决策串起来,就是一条轨迹(trajectory)。表面上看,Agent 的轨迹建模与传统 LLM 非常相似,二者的本质差异不在形式,而在轨迹的结构与环境属性:• Policy:决策采样动作分布
• 状态转移:具有非确定性性(API / 用户 / 外部系统)
• 动作空间:组合空间(工具选择× 参数生成)接近无限且具备结构化特征
• 优化目标:让整条轨迹的最终效果更好
• Policy 梯度:强化/抑制当时的决策
• 信用分配:当前这一步的决策,到底好不好?
Agent 的本质不是生成文本,而是生成决策轨迹,这个视角转换直接改变了我们的系统设计:
数据层不再存对话消息,而是存结构化轨迹——每一步的 observation、thought、action、tool_result,加上 token IDs 和 log-probs。

奖励层不再评单个 response,而是评整条轨迹——路径选得对不对、结果好不好、步数够不够精简。
黄金路径: [calendar_api → rag_query → email_compose → translate]
轨迹 A: [calendar_api → rag_query → email_compose → translate] → path_score: 1.0
轨迹 B: [search → search → calendar_api → translate] → path_score: 0.3
轨迹 C: [calendar_api → email_compose](遗漏 RAG) → path_score: 0.5
环境层要包括任务生成器、动作执行器、ReAct 循环管理和多维度奖励模块,环境控制任务各类任务:Skill 调用(如翻译、摘要)、Tool 调用(如read、edit等)和知识库 RAG(如内部文档检索)。
还有一个容易被忽视的细节:mask 设计。多轮交互中不是所有 token 都该参与训练。只对 agent 的可控决策 token 进行训练。训练错误的 mask,模型会去学习”预测 API 会返回什么”,而不是”什么时候该调 API”。
[system prompt] → mask = 0 (不训练)
[user query] → mask = 0 (不训练)
[assistant turn 1] → mask = 1 (训练: Thought + Action)
[observation 1] → mask = 0 (不训练: 环境反馈)
[assistant turn 2] → mask = 1 (训练)
[observation 2] → mask = 0 (不训练)
[assistant final] → mask = 1 (训练: 最终回答)
四、架构:快慢分离的三条学习路径
建模清楚了,接下来聊工程。我们最终落地的架构:不能只有一条学习路径, 不同类型的问题需要不同速度的响应。
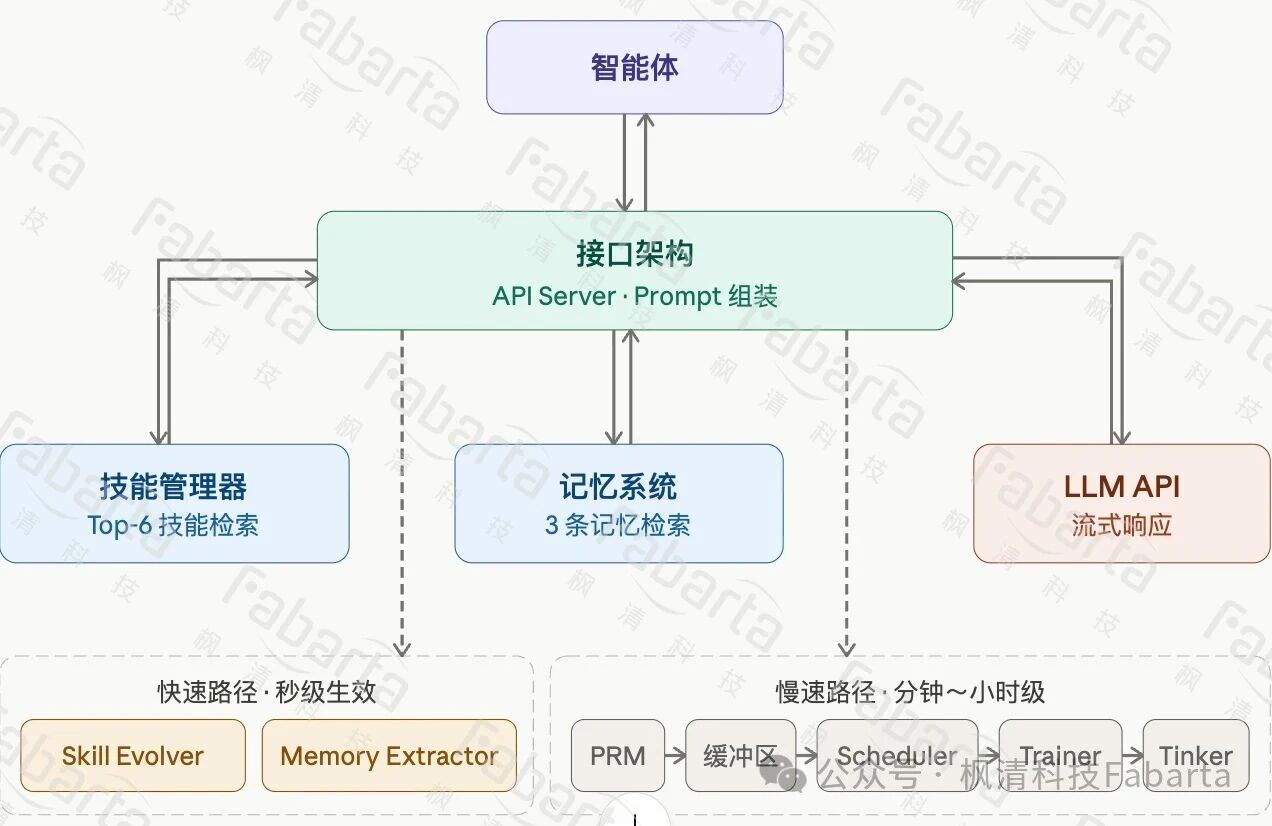
三条路径,覆盖不同时间尺度
经验注入(秒级)。对话结束后,系统自动提取可复用的模式—对话结束后,系统从轨迹中自动抽象可复用的决策策略与问题模式(Skill & Memory 进化),并结构化存储。从历史“Skill 与 Memory”中召回策略片段,在推理阶段作为决策先验注入模型,引导 action selection,而非改变模型参数。
在线微调(小时级)。这里才是真正的 RL。核心洞察:用户发的下一条消息本身就是天然奖励。“谢谢,搞定了” = 正信号。“不对,我要的不是这个” = 负信号。更有价值的是文字纠正——“你应该先查知识库”这类反馈可以提取为 token 级的方向性信号,模型不仅知道”错了”,还知道优化方向。
离线模拟(天级)。解决冷启动。构建模拟环境让 Agent 反复尝试,用多维度奖励评分,批量生成训练数据。Agent 上线之前就能具备基础能力。
三条路径不是互相替代的。经验注入解决”让今天遇到的问题明天不再犯”;在线微调解决”反复出现的同类错误从权重层面修复”;离线模拟解决”上线前的冷启动和新类型扩展”。
奖励信号怎么融合
尽管稀疏/模糊条件下的 样本复杂度下界、信用分配的信息论边界、非平稳奖励的收敛性保证 仍缺乏统一框架。但从工程上可以做一些平衡,借助 LLM 与偏好学习实现语义对齐,通过形式化约束与人机协同守住安全边界。在关键决策节点引入 human-in-the-loop 偏好标注或否决机制,用少量高质量反馈校正奖励偏差:
• 用户显式反馈(点赞/文字纠正)最准确,但极稀疏——不到 5% 的对话会有。
• LLM 自动评分(用模型判断回答质量)覆盖率能到 80%,但 Judge 模型自身有偏差。
• 业务指标(转化率、解决率)是终极真相,但延迟大、归因难。
三种信号各有优劣,我们的策略:
LLM 评分作为日常训练的主力数据源,采用多维度奖励设计:答案质量(40%)、路径正确性(30%)、效率(20%)和格式规范(10%),最终综合得分是各维度按权重加权得到,用于同时衡量“答对了什么”和“是怎么做到的”。
用户显式反馈权重最高,出现时覆盖 LLM 评分。用户的隐式反馈依然赋予较高权重,例如下一轮回复中的纠偏,提取语义后,生成hint类型的反馈信号。业务指标作为兜底——如果 LLM 评分在涨但业务指标在跌,说明模型在”讨好”评分器而不是真的变好了。这时候自动触发回滚。
自动调参:持续学习的控制层
在线微调跑通之后,瓶颈会很快从“有没有数据/奖励”,转移到“策略怎么调”。训练数据怎么选、奖励如何加权、探索强度、训练节奏——这些表面是超参数,本质是学习策略本身。在多 Agent、多阶段、多模型权重环境下,这套策略是动态变化的,人工调参不可扩展。一个思路借鉴控制论里面的二阶控制:引入 meta-agent,根据训练反馈动态调整训练配置,实现 policy over policy。类似 Andrej Karpathy 的 autoresearch,本质也是在做同一件事:不是优化单次任务,而是在轨迹空间中搜索更优策略。
三条学习路径解决“怎么学”,这一层解决“学什么、优先级如何分配”。缺了这一层,系统仍然是“人驱动优化”;补上之后,才开始具备自进化能力。当前大多数系统停留在前者,而真正的分水岭在后者。
上线安全
RL 训练最让工程团队焦虑的不是”训不出来”,是”训坏了怎么办”。在一个持续学习系统中,完全禁止退化是不现实的,关键是能否在退化扩散之前识别并截断它。把回滚本身做成优化过程的一部分——相当于在策略空间中做“负向更新”,当回滚和错误放大的成本最够低时,系统迭代的速度才会持续加快。为此我们需要至少三层外部防护:
- 评估门控:训练完自动跑 benchmark。通用能力不能下降 + 目标能力有提升,才允许进入下一步。
- 灰度发布:新版本只接部分流量,观察真实环境下的行为分布,而不是只看离线指标。
- 一键回滚:同时监控 reward、业务指标和行为分布(如工具调用路径、失败模式)。很多时候模型“变差”不是体现在平均分,而是某一类轨迹开始系统性退化。模型路由的自由切换可以实现一键回到上一个版本,增量权重的加载可以缩短模型启动时效。
整体架构
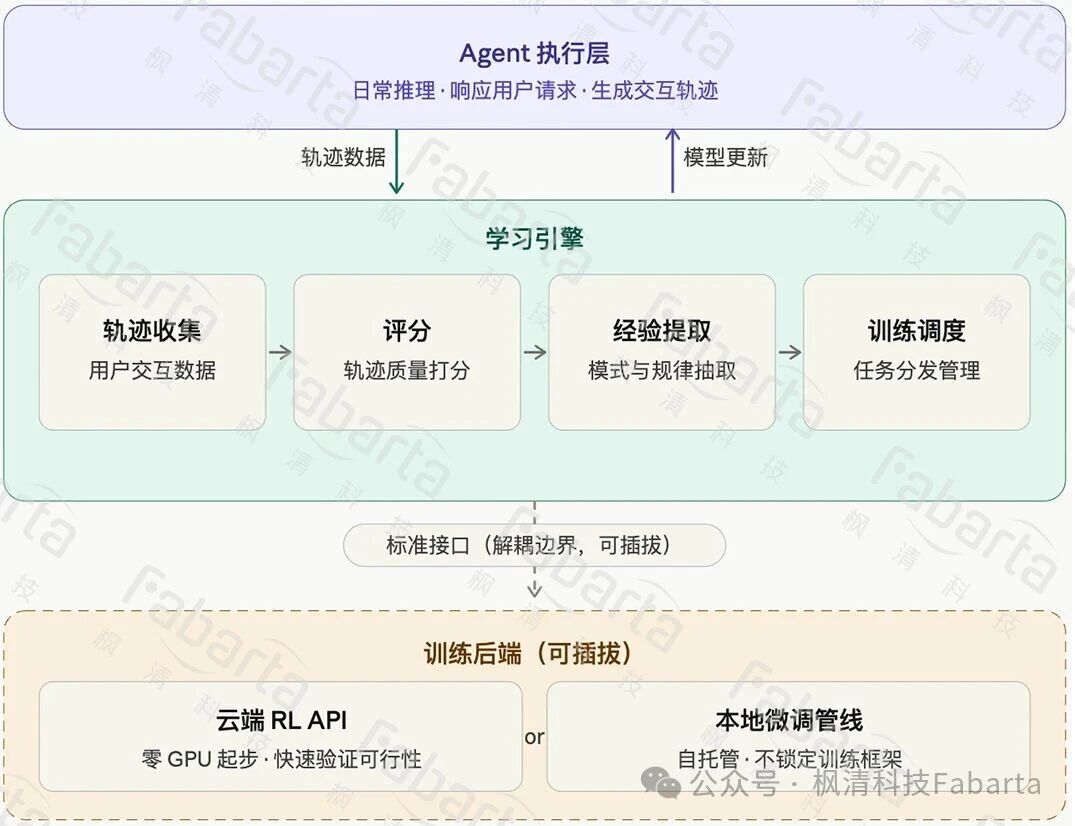
最终的系统分三层:
Agent 执行层负责日常推理和服务用户;
学习引擎负责轨迹收集、环境的构建,评分维度生成、经验提取和训练调度;
训练后端可插拔——可以是云端 RL API(零 GPU 起步),也可以是本地的微调管线。
关键的设计决策是学习引擎和训练后端解耦。平台管数据,训练算法通过标准接口接入,这样既能快速用云端 API 验证可行性,也不会被锁死在某个特定的训练框架上。
五、一个多模态证照识别 Agent 的进化之路
背景
某行业的供应商准入流程要审核大量证照——营业执照、经营许可证、授权委托书。种类多,版式杂,每份人工录入要 5-10 分钟。我们需要一个多模态 Agent 把证照图片变成结构化 JSON。
但这事不好做。证照涉及企业隐私,不能随便拿来标注。真实可用的数据只有几百条级别。证件类型多达五六种,每种的版式和字段定义都不一样。而且部署环境要求轻量——不可能上 32B 的大模型,得控制在 4B。
第一步:冷启动——合成数据 + 蒸馏
没有数据怎么训练?我们来造。
从仅有的十几份真实证件出发,搭了一套自动化合成引擎。先从真实证件中提取空白模板——保留版面结构、印章位置、字段标签,擦掉所有填写内容。然后用 LLM 批量生成结构化字段数据:企业名称要和地址的省市匹配,统一社会信用代码必须是 18 位,有效期要合理。再把这些数据填回模板,渲染成图片。最后加上图像扰动——旋转几度、加点模糊、调下颜色、模拟反光——让合成数据更接近真实扫描件。
十几条真实样本,最终生成了 3800 多条训练数据。
然后做蒸馏。教师模型是 Qwen3-VL-32B,学生是 Qwen3-VL-4B,用 GKD + SFT 的方式压缩。
为了让推理多样化,我们设计了两种模式交替使用:声明模式(先列出字段清单,再逐个在图上定位取证)和发现模式(模拟人眼从上到下扫描,看到冒号、下划线、表格等视觉线索后提取字段)。
最关键的一步叫过河拆桥:训练时用的所有辅助 prompt(包含 GT 答案的系统消息、视角触发器)在打包训练数据时全部丢弃,只留下最通用的 user prompt 加上教师的推理过程和 GT 答案。这样学生模型在推理时面对一个毫无提示的通用 prompt,也能自发展现出教师那样的结构化推理能力。
第二步:突破长尾——GSPO 强化学习
蒸馏做完,大部分字段的准确率已经到了 85-90%。但剩下的 10% 才是真正让人头疼的:许可范围这种几百字的长文本、模糊不清的手写签名区域、被印章盖住的关键字段。这些靠加数据不好使了,需要 RL 来精雕细琢。
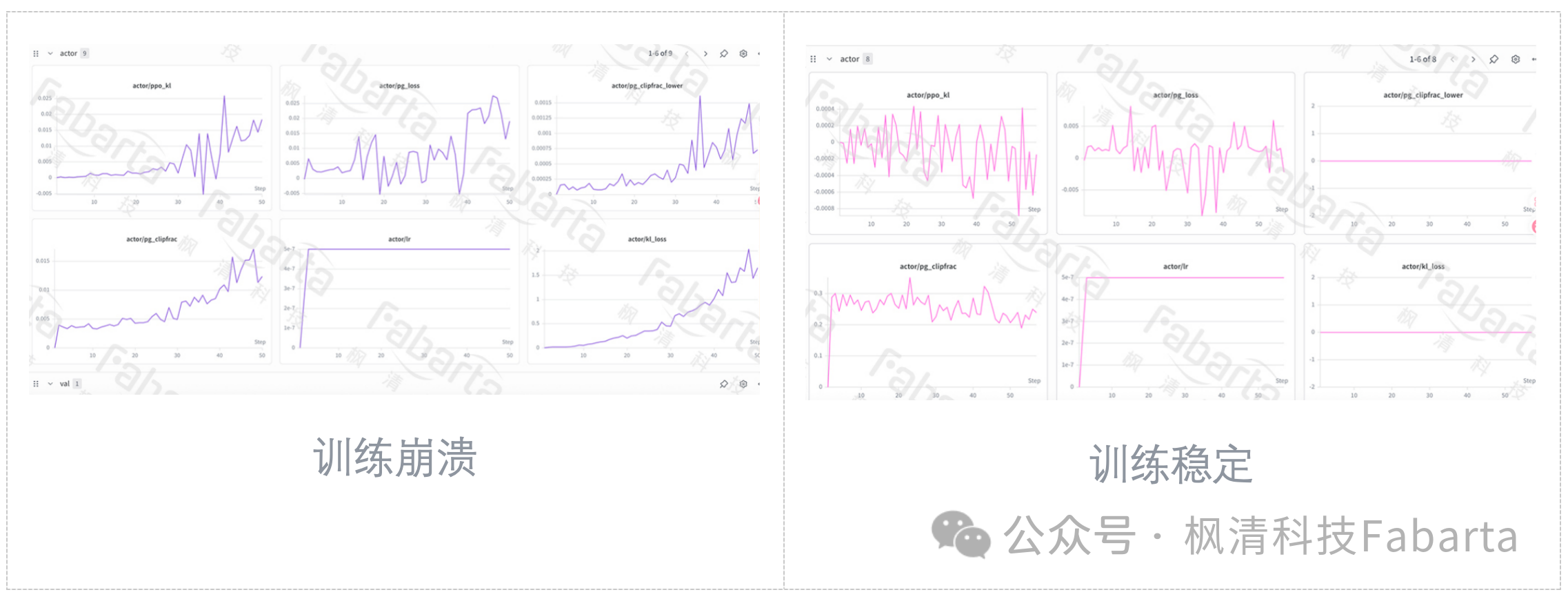
奖励函数是最难的部分,我们前后迭代了五版,训练才稳定下来。
score = 0.05 + 0.95 × F1⁴
0.05 是格式保底分——只要输出能被解析成 JSON 就给,防止模型在探索初期因为格式崩溃而完全拿不到分。
F1 是字段级的精确率和召回率的调和均值。用 F1 就不需要单独设计幻觉惩罚和漏提惩罚了——多输出假字段,precision 自动下降;少输出真字段,recall 自动下降,从数学上堵住了reward hacking的路。
四次方是整个设计里最精彩的部分。 SFT 之后模型的 F1 已经到了 0.9 左右。如果用线性奖励,0.9 和 1.0 只差 0.1,梯度太弱,模型没有动力去消除最后几个错误。但 0.9 的四次方是 0.65,1.0 的四次方是 1.0——差距从 0.1 被拉到了 0.35。这种指数级放大让模型在训练后期依然有强烈的动力去抠细节。
字段匹配用的是贪心二分图:把 GT 字段和预测字段做一对一最优配对,key 相似度低于 0.5 的直接不配(防止风马牛不相及的字段强行配对),value 相似度取平方(对”差不多对”施加更严厉的惩罚)。
第三步:走向持续学习
蒸馏和 GSPO 做完,模型上线。这时候持续学习的闭环自然形成了:用户上传证照,模型提取字段,业务系统自动校验。统一社会信用代码的校验位不对?自动负信号。身份证号格式不合法?自动负信号。人工审核通过并提交?正信号。这些信号零成本、零延迟、100% 准确。证照识别是所有 Agent 场景中奖励信号最清晰的——结果对不对,机器和人都能立即判断。轨迹数据持续入库,积累到一定量就触发下一轮 GSPO 训练,灰度发布上线。遇到新证件类型(比如药品经营许可证),合成数据引擎直接复用——做一个新模板、跑一遍 Label 生成、训练,整个流程已经是标准化的了。
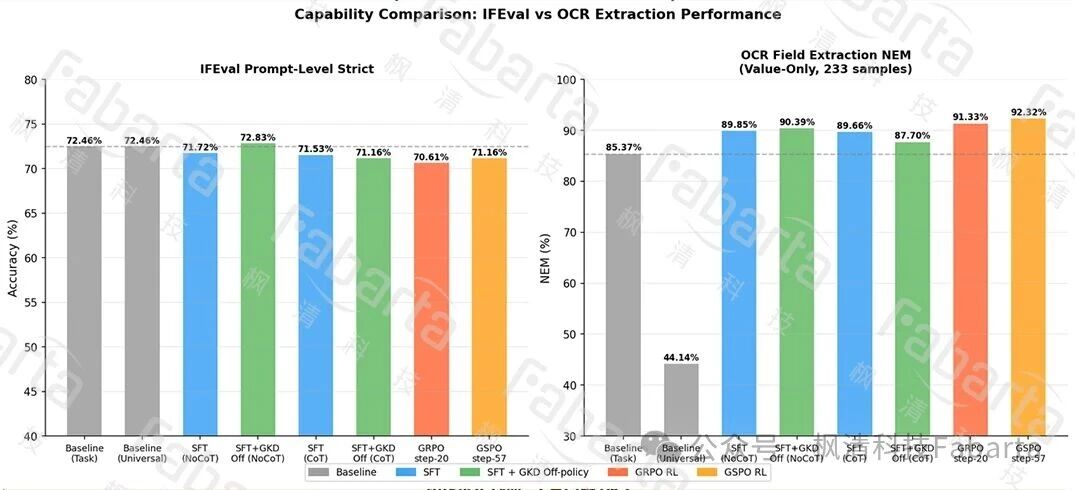
模型更新后效果和知识遗忘对比
经验总结
第一,奖励函数需要精雕细琢。我们在 GSPO 算法上没做任何改动,但奖励函数迭代了五版才稳定。每一版都有不同形式的 reward hacking,不亲手踩过根本想不到。
第二,字段之间差异巨大。简单字段(日期、法人姓名)蒸馏后就接近满分了,再投入 RL 训练边际收益很小。长文本字段(经营范围、许可范围)才是持续学习真正值得投入的地方,资源应该集中在这里。
第三,合成与真实的 gap 是真实存在的,不要被合成数据的量迷惑。3800 条合成不如 33 条真实,这个比例在我们的实验中反复验证。合成数据是必要的——没有它冷启动都做不了——但它是地板不是天花板。
第四,多模态证照识别 Agent 的场景收敛。与大量交互式工具调用的复杂智能体相比,证照识别的链路呈单一化特征,任务执行路径更确定化,任务流程被约束,在模型的Agentic能力上并未形成复杂的组合环境探索,伴随更多智能体类型的应用,算法和训练基础设施都会面临新的挑战。
六、Agent 平台的长期竞争力在于高质量交互轨迹的持续积累与利用能力
Agent 平台的核心壁垒不是”能跑多少 Agent”,而是”Agent 进化的速度”。
能跑 Agent 是门槛,不是壁垒。真正的竞争力来自一个自增强的飞轮:Agent 服务用户,产出结构化轨迹;轨迹被评分、入库;积累到一定量,触发训练,模型变强;更好的 Agent 吸引更多用户,产出更多轨迹。这个飞轮的三个特性,让它一旦转起来就很难被追上。
数据独占性。每个企业的轨迹数据是独有的。某个行业售前 Agent 积累的术语库、常见客户顾虑、成功话术——这些数据训出来的模型,别人拿通用数据训一百遍也训不出来。
复利效应。经验注入秒级见效是利息,RL 微调持久提升是本金增长,两者叠加就是复利。第一千个用户看到的 Agent 和第一个用户看到的,已经不是同一个模型了。
依然面临着巨大的挑战和开放问题
环境与真实的 gap。 前面说了,3800 条合成 < 33 条真实。合成数据能解决 80% 的问题,但最后 20% 必须靠生产数据。怎么缩小这个 gap?更好的合成引擎?更智能的数据增强?还是接受它就是存在的,把精力放在更高效地利用真实数据上?RL 需要数据,数据来自交互,Agent 上线初期交互量很小。企业新 Agent 上线初期可能一周才一百多条对话,有反馈的不到 十几条。
奖励函数的工程成本。我们的 F1⁴ 奖励函数经历了五轮迭代才稳定,这个试错成本不是每个团队都能承受的。行业需要的是可复用的”奖励模板”——证照识别用 F1 + 二部图匹配,客服用满意度 + 解决率,代码生成用测试通过率。这些能不能标准化?
Scaling Law 在 Agent RL 中是否存在? 更多轨迹数据是否总能带来更好的模型?我们观察到单类型 450 条和 950 条之间有显著提升,但多类型混合训练的收益在递减。在大模型训练中有大量的数据混合策略,这些是否合适?到了什么量级会遇到瓶颈?目前没有人有清晰的答案。
企业级隐私。 用户交互数据用于训练,边界在哪?租户的隔离, RBAC, 租户间/不同智能体间权重的热更新等等。证照场景还涉及企业隐私。技术架构必须在设计之初就把数据隔离、匿名化和知情同意考虑进去,不能事后再补。
七、最后说一句
我们新一代的企业智能体平台已发布:专为核心业务打造的 AI Agent 平台EKC 2.0 提供从构建到上线的完整 Agent 工具链——多智能体编排、多渠道触达、100+ 内置工具与自动化评测,助力企业在复杂业务场景中稳定运行 AI Agent。